Анемичный group php. Настраиваем php-fpm. Что такое PHP-FIG
Если вы занимались разработкой PHP последние несколько лет, то наверняка знаете о проблемах этого языка. Зачастую можно услышать, что это фрагментированный язык, инструмент для взломов, что он не имеет настоящей спецификации и т.д. Реальность же такова, что PHP сильно «вырос» в последнее время. Версия PHP 5.4 приблизила его к полной объектной модели и предоставила много новой функциональности.
И это все, конечно, хорошо, но что насчёт фрейморков? На PHP их существует огромное множество. Стоит только начать искать и вы поймете, что вам не хватит жизни изучить их все, потому что новые фрейморки появляются постоянно и в каждом изобретается что-то свое. Так как же превратить это в нечто, что не отталкивает разработчиков и позволяет легко переносить функционал из одного фреймворка в другой?
Что такое PHP-FIG
PHP-FIG (PHP Framework Interop Group) - организованная группа разработчиков, цель которой находить способы совместной работы нескольких фрейморков.
Только представьте: сейчас вы поддерживаете проект на Zend Framework, которому понадобился модуль корзины магазина. Вы уже писали такой модуль для предыдущего проекта, который был на Symphony. Не делать же его снова? К счастью и ZendF и Symphony являются частью PHP-FIG, так что можно импортировать модуль с одного фреймворка в другой. Разве не здорово?
Давайте узнаем, какие фреймворки входят в PHP-FIG
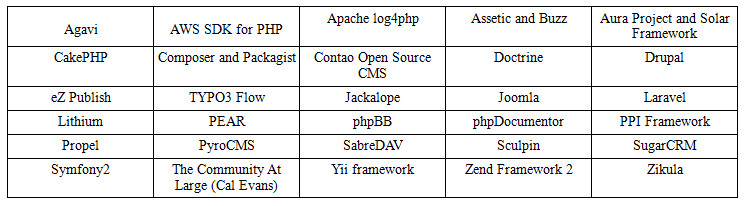
Участники PHP-FIG
Любой разработчик может внести свой фреймворк в список участников PHP-FIG. Тем не менее за это необходимо будет заплатить некую сумму, так что если у вас нет поддержки сообщества вы врядли согласитесь на это. Это сделано для того, чтобы предотвратить регистрацию миллионов микрофреймворков без какой-либо репутации.
Текущие участники:
Что такое PSR?
PSR (PHP Standarts Recomendations) - стандартные рекомендации, результат работы PHP-FIG. Одни члены Группы предлагают правила для каждого PSR, другие голосуют в поддержку этих правил или за их отмену. Обсуждение проходит в Google Groups, а наборы PSR доступны на официальном сайте PHP-FIG.
Давайте рассмотрим некоторые PSR:
Первый шаг на пути объединения фреймворков - наличие общей структуры директорий, поэтому и был принят общий стандарт автозагрузки.
- Пространство имен (namespace) и класс должны иметь структуру \\(\)*.
- Каждое пространство имен должно содержать пространство верхнего уровня («Vendor Name»).
- Каждое пространство имен может иметь сколько угодно уровней.
- Каждый разделитель пространства имен конвертируется в DIRECTORY_SEPARATOR при загрузке.
- Каждый символ «_» в CLASS NAME конвертируется в DIRECTORY_SEPARATOR.
- К полностью определённому пространству имен и классу добавляется «.php» при загрузке.
Пример функции автозагрузки:

PSR-1 - Basic Coding Standart
Эти PSR регулируют основные стандарты, главная идея которых - если все разработчики используют одни стандарты, то перенос кода можно производить без всяких проблем.
- В файлах должны использоваться только теги
- В файлах должна использоваться только кодировка UTF-8 without BOM.
- Имена пространств и классы должны следовать PSR-0.
- Имена классов должны быть объявлены в нотации StudlyCaps.
- Константы класса должны быть объявлены в верхнем регистре, разделенные подчеркиваниями.
- Методы должны быть объявлены в нотации camelCase.
PSR-2 - Coding Style Guide
Это расширенные инструкции для PSR-1, описывающие правила форматирования кода.
- Код должен соответствовать PSR-1.
- Вместо табуляции должны использоваться 4 пробела.
- Не должно быть строгого ограничения на длину строки, рекомендуемая длина - до 80 символов.
- Должна быть одна пустая строка после объявления пространства имен.
- Скобки для классов должны открываться на следующей строке после объявления и закрываться после тела класса (то же самое для методов).
- Видимость методов и свойств должна быть обязательно определена (public, private).
- Открывающие скобки для управляющих структур должны находиться на той же строке, закрывающие скобки должны быть на следующей строке после тела структуры.
- Пробелы не ставятся после открывающихся круглых скобок методов управляющих структур и перед закрывающимися скобками.
PCR-3 - Logger Interface
В PCR-3 регулируется логгинг, в частности основные девять методов.
- LoggerInterface предоставляет 8 методов для логирования восьми RFC 5424 уровней (debug, notice, warning, error, critical, alert, emergency).
- Девятый метод log() принимает на вход уровень предупреждения первым параметром. Вызов метода с параметром уровня предупреждения должен возвращать такой же результат, как и вызов метода определенного уровня лога (log(ALERT) == alert()). Вызов метода с неопределённым уровнем предупреждения должен генерировать Psr\Log\InvalidArgumentException.
Так же как и PSR-0, PSR-4 предоставляет улучшенные методы автозагрузки
- Термин «класс» относится к классам, интерфейсам, трейтам и другим похожим структурам
- Полностью определённое имя класса имеет следующую форму: \
(\ )*\ - При загрузке файла, соответствующему полностью определённому имени класса:
- Непрерывная серия одного или более ведущих пространств имен, не считая ведущего разделителя пространства имен, в полностью определенном имени класса соответствует по крайней мере одной «корневой директории».
- Имена директорий и поддиректорий должны соответствовать регистру пространства имен.
- Окончание полного имени класса соответствует имени файла с окончанием.php. Регистр имени файла обязан соответствовать регистру окончания полного имени класса.
- Реализация автозагрузчика не должна бросать исключения, генерировать ошибки любого уровня и не обязана возвращать значение.
Заключение
PHP-FIG изменяет способы написания фреймворков, но не то как они работают. Клиенты часто обязывают работать с существующим кодом внутри фреймворка или определяют с каким фреймворком вы должны работать над проектом. PSR рекомендации делают жизнь разработчиков на много легче в этом отношении и это здорово!
16.09.2016Попробуем определить каким образом можно повысить производительность сервера приложений на базе php-fpm, а также сформировать чек-лист для проверки конфигурации fpm процесса.
Прежде всего стоит определить расположение файла-конфигурации пула. Если вы устанавливали php-fpm из системного репозитория, то конфигурация пула www будет расположена примерно тут /etc/php5/fpm/pool.d/www.conf . В случае если используется свой билд или другая ОС (не debian) следует поискать расположение файла в документации, или указывать его вручную.
Попробуем рассмотреть конфигурацию подробней.
Переходим на UNIX-сокеты
Наверное первое, на что следует обратить внимание, это то как проходят данные от веб-сервера к вашим php процессам. Это отражено в директиве listen:
listen = 127.0.0.1:9000
В случае если установлен адрес:порт, то данные идут через стек TCP, и это наверное не очень хорошо. Если же там путь к сокету, например:
listen = /var/run/php5-fpm.sock
то данные идут через unix-сокет, и можно пропустить этот раздел.
Почему все таки стоит перейти на unix-сокет? UDS (unix domain socket), в отличии от комуникции через стек TCP, имеют значительные преимущества:
- не требуют переключение контекста, UDS используют netisr)
- датаграмма UDS записываться напрямую в сокет назначения
- отправка дейтаграммы UDS требует меньше операций (нет контрольных сумм, нет TCP-заголвоков, не производиться маршрутизация)
TCP средняя задержка: 6 us UDS средняя задержка: 2 us PIPE средняя задержка: 2 us TCP средняя пропускная способность: 253702 msg/s UDS средняя пропускная способность: 1733874 msg/s PIPE средняя пропускная способность: 1682796 msg/s
Таким образом, у UDS задержка на ~66% меньше и пропускная способность в 7 раз больше TCP. Поэтому, скорей всего стоит перейти на UDS. В моем случае сокет будет расположен по адресу /var/run/php5-fpm.sock .
; закоментируем это - listen = 127.0.0.1:9000 listen = /var/run/php5-fpm.sock
Также следует убедиться что веб-сервер (или любой другой процесс, которому необходима коммуникация) имеет доступ на чтение/запись в ваш сокет. Для этого существуют настройки listen.grup и listen.mode Проще всего - запускать оба процесса от одного пользователя или группы, в нашем случае php-fpm и веб-сервер будет запущен с группой www-data :
listen.owner = www-data listen.group = www-data listen.mode = 0660
Проверяем выбранный механизм обработки событий
Для работы с эффективной работы с I/O (вводом-выводом, дескрипторами файлов/устройств/сокетов) стоит проверить правильно ли указана настройка events.mechanism . В случае если php-fpm установлен из системного репозитория, скорей всего там все в порядке - он либо не указан (устанавливаться автоматически), либо указан корректно.
Его значение зависит от ОС, для чего есть подсказка в документации:
; - epoll (linux >= 2.5.44) ; - kqueue (FreeBSD >= 4.1, OpenBSD >= 2.9, NetBSD >= 2.0) ; - /dev/poll (Solaris >= 7) ; - port (Solaris >= 10)
К примеру если мы работаем на современном linux-дистрибутивe нам необходим epool:
events.mechanism = epoll
Выбор типа пула - dynamic / static / ondemand
Также, стоит обратить внимание на настройки менеджер процессов (pm). По сути это главный процесс (master process), который будет управлять всеми дочерними (которые выполняют код приложения) по определенной логике, которая собственно и описана в файле конфигурации.
Всего доступно 3 схемы управления процессами:
- dynamic
- static
- ondemand
Наиболее простой - это static . Схема его работы заключается в следующем: запустить фиксированное количество дочерних процессов, и поддерживать их в рабочем состоянии. Данная схема работы не очень эффективна, так как количество запросов и их нагрузка может меняться время от времени, а количество дочерних процессов нет - они всегда занимают определенный объем ОЗУ и не могут обрабатывают пиковые нагрузки в порядке очереди.
dynamic пул позволят решить эту проблему, он регулирует количество дочерних процессов исходя из значений конфигурационного файла, изменяя их в большую или меньшую сторону, в зависимости от нагрузки. Данный пул больше всего подходит для сервера приложений, в котором необходима быстрая реакция на запрос, работа с пиковой нагрузкой, требуется экономия ресурсов (за счет уменьшения дочерних процессов при простое).
ondemand пул очень похож на static , но он не запускает дочерних процессов при старте главного процесса. Только когда придет первый запрос - будет создан первый дочерний процесс, и по истечении определенного времени ожидания (указанного в конфигурации) он будет уничтожен. Потому он актуален для серверов с ограниченными ресурсами, или той логики которая не требует быстрой реакции.
Утечки памяти и OOM killer
Следует обратить внимание на качество приложений которые будут выполняться дочерними процессами. Если качество приложения не очень высоко, или используются множество сторонних библиотек, то необходимо подумать о возможных утечках памяти, и установить значения таким переменным:
- pm.max_requests
- request_terminate_timeout
pm.max_requests это максимальное количество запросов, которое обработает дочерний процесс, прежде чем будет уничтожен. Принудительное уничтожение процесса позволяет избежать ситуации в которой память дочернего процесса “разбухнет” по причине утечек (т.к процесс продолжает работу после от запроса к запросу). С другой стороны, слишком маленькое значение приведет к частым перезапускам, что приведет к потерям в производительности. Стоит начать с значения в 1000, и далее уменьшить или увеличить это значение.
request_terminate_timeout устанавливает максимальное время выполнения дочернего процесса, прежде чем он будет уничтожен. Это позволяет избегать долгих запросов, если по какой-либо причине было изменено значение max_execution_time в настройках интерпретатора. Значение стоит установить исходя из логики обрабатываемых приложений, скажем 60s (1 минута).
Настройка dynamic пула
Для основного сервера приложения, ввиду явных преимуществ, часто выбирают dynamic пул. Его работа описана следующими настройками:
- pm.max_children - максимальное количество дочерних процессов
- pm.start_servers - количество процессов при старте
- pm.min_spare_servers - минимальное количество процессов, ожидающих соединения (запросов для обработки)
- pm.max_spare_servers - максимальное количество процессов, ожидающих соединения (запросов для обработки)
Для того чтобы корректно установить эти значения, необходимо учитывать:
- сколько памяти в среднем потребляет дочерний процесс
- объем доступного ОЗУ
Выяснить среднее значение памяти на один php-fpm процесс на уже работающем приложении можно с помощью планировщика:
# ps -ylC php-fpm --sort:rss S UID PID PPID C PRI NI RSS SZ WCHAN TTY TIME CMD S 0 1445 1 0 80 0 9552 42588 ep_pol ? 00:00:00 php5-fpm
Нам необходимо среднее значение в колонке RSS (размер резидентной памяти в килобайтах). В моем случае это ~20Мб. В случае, если нагрузки на приложения нет, можно использовать Apache Benchmark, для создания простейшей нагрузки на php-fpm.
Объем общей / доступной / используемой памяти можно посмотреть с помощью free :
# free -m total used free ... Memory: 4096 600 3496
Total Max Processes = (Total Ram - (Used Ram + Buffer)) / (Memory per php process) Всего ОЗУ: 4Гб Используется ОЗУ: 1000Мб Буфер безопасности: 400Мб Память на один дочерний php-fpm процесс (в среднем): 30Мб Максимально возможное кол-во процессов = (4096 - (1000 + 400)) / 30 = 89 Четное количество: 89 округлили в меньшую сторону до 80
Значение остальных директив можно установить исходя из ожидаемой нагрузки на приложение а также учесть чем еще занимается сервер кроме работы php-fpm (скажем СУБД также требует ресурсов). В случае наличия множества задач на сервере - стоит снизить к-во как начальных / максимальных процессов.
К примеру учтем что на сервере находиться 2 пула www1 и www2 (к примеру 2 веб-ресурса), тогда конфигурация каждого из них может выглядеть как:
pm.max_children = 40 ; 80 / 2 pm.start_servers = 15 pm.min_spare_servers = 15 pm.max_spare_servers = 25
Язык программирования PHP прошел большой путь от инструмента для создания персональных страниц до языка общего назначения. Сегодня он установлен на миллионах серверов по всему миру, используется миллионами разработчиков, которые создают множество самых разнообразных проектов.
Он прост в изучении и крайне популярен, особенно среди новичков. Поэтому вслед за развитием языка последовало и мощное развитие сообщества вокруг него. Огромное количество скриптов, на все случаи жизни, разные библиотеки, фреймворки. Отсутствие же единых норм оформления и написания кода, привели к возникновению огромного пласта информационных продуктов построенных на собственных принципах разработчика этого продукта. Особенно это было заметно при работе с различным PHP фреймворками , которые долгое время представляли собой замкнутую экосистему, не совместимую с другими фреймворками, несмотря на то, что задачи, которые решаются ими часто схожи.
В 2009 году разработчики нескольких фреймворков договорились о создании сообщества PHP Framework Interop Group (PHP-FIG) , которое бы вырабатывало рекомендации для разработчиков. Важно подчеркнуть, что речь не идет о ISO-стандартах , более правильно говорить о рекомендациях. Но так как создавшие PHP-FIG сообщество разработчики представляют крупные фреймворки, то их рекомендации представляют серьёзный вес. Поддержка PSR (PHP standart recommendation) стандартов позволяет обеспечивать совместимость, что облегчает и ускоряет разработку конечного продукта.
Всего на момент написания статьи существует 17 стандартов, причем 9 из них являются утвержденными, 8 находятся в стадии проекта, активно обсуждаются, 1 стандарт не рекомендован к использованию.
Теперь перейдем непосредственно к описанию каждого стандарта. Заметьте, что я не буду здесь подробно разбирать каждый стандарт, скорее это небольшое введение. Также в статье будут рассматриваться только те стандарты PSR , которые официально приняты, т.е. находятся в статусе Accepted .
PSR-1. Основной стандарт кодирования
Он представляет собой наиболее общие правила, такие как, например, использование тегов PHP , кодировка файлов, разделения места объявления функции, класса и места их использования, именование классов, методов.
PSR-2. Руководство по стилю кода
Является продолжением первого стандарта и регулирует вопросы использования в коде табуляции, переводов строк, максимальную длину строк кода, правила оформления управляющих конструкций и т.д.
PSR-3. Интерфейс протоколирования.
Этот стандарт разработан для того, чтобы обеспечить (журналирование) логирование в приложениях, написанных на PHP .
PSR-4. Стандарт автозагрузки
Это, наверное, самый важный и нужный стандарт, которому будет посвящена отдельная, подробная статья. Классы, которые реализуют PSR-4 , могут быть загружены единым автозагрузчиком, что позволяет частям и компонентам из одного фреймворка или библиотеки быть использованными в других проектах.
PSR-6. Интерфейс кеширования
Кэширование используется для повышения производительности системы. И PSR-6 позволяет стандартно сохранять и извлекать данные из кэша, используя унифицированный интерфейс.
PSR-7. Интерфейс HTTP-сообщений
При написании мало-мальски сложных сайтов на PHP , почти всегда приходиться работать с HTTP заголовками . Конечно, язык PHP предоставляет нам уже готовые возможности для работы с ними, такие как суперглобальный массив $_SERVER , функции header() , setcookie() и т.д., однако их ручной разбор чреват ошибками, да и не всегда можно учесть все нюансы работы с ними. И вот, чтобы облегчить работу разработчику, а также сделать единообразным интерфейс взаимодействия с HTTP протоколом был принят данный стандарт. Более подробно об этом стандарте я расскажу в одной из следующих статей.
PSR-11. Интерфейс контейнера
При написании PHP программы часто приходится использовать сторонние компоненты. И чтобы не заблудиться в этом лесу зависимостей были придуманы различные методы управления зависимостями кода, зачастую несовместимые между собой, которые данный стандарт и приводит к общему знаменателю.
PSR-13. Гипермедиа ссылки
Данный интерфейс призван облегчить разработку и использование прикладных программных интерфейсов (API ).
PSR-14. Интерфейс простого кэширования
Является продолжением и улучшением стандарта PSR-6
Таким образом, сегодня мы с Вами рассмотрели PSR стандарты . За актуальной информацией о статусе стандартов можете обращаться по адресу
Поскольку развитие технологий привело к тому, что у каждого программиста теперь есть собственный компьютер, в качестве побочного эффекта имеем тысячи разнообразных библиотек, фреймворков, сервисов, API и т.д. на все случаи жизни. Но когда этот случай жизни наступает, возникает проблема - что их этого использовать и что делать если оно не совсем подходит - переписывать, писать с нуля свое или прикручивать несколько решений для разных вариантов использования.
Думаю, многие замечали, что зачастую создание проекта сводится не столько к программированию сколько к написанию кода интеграции нескольких готовых решений. Иногда такие комбинации превращаются в новые решения, которые можно неоднократно использовать в последующих задачах.
Перейдем к конкретной «ходовой» задаче - объектная прослойка для работы с базами данных в PHP. Решений великое множество, начиная от PDO и заканчивая многоуровневыми (и, на мой взгляд, не совсем уместными в PHP) ORM движками.
Большинство этих решений перекочевали в PHP из других платформ. Но зачастую авторы не учитывают особенности PHP, которые позволили бы резко упростить как написание, так и использование портируемых конструкций.
Одной из распространенных архитектур для данного класса задач является паттерн Active Record. В частности, по этому шаблону строятся так называемые Entity (сущности), в том или ином виде использующиеся в ряде платформ, начиная от персистентных бинов в EJB3 заканчивая EF в.NET.
Итак, построим подобную конструкцию для PHP. Соединим между собой две клёвые штуки - готовую библиотеку ADODB и слаботипизированность и динамические свойства объектов языка PHP.
Одной из многочисленных фич ADODB является так называемая автогенерация SQL запросов для вставки (INSERT) и обновления (UPDATE) записей на основе ассоциативных массивов с данными.
Собственно нет ничего военного взять массив, где ключи - имена полей а значения - соответственно, данные и сгенерировать строку SQL запроса. Но ADODB делает это более интеллектуально. Запрос строится на основе структуры таблицы, которая предварительно считывается с схемы БД. В результате во-первых, в sql попадают только существующие поля а не всё подряд, во-вторых, учитывается тип поля - для строк добавляются кавычки, форматы дат могут формироваться на основе timestamp если ADODB видит оный вместо строки в передаваемом значении и т.д.
Теперь зайдем со стороны PHP.
Представим такой класс (упрощенно).
Class Entity{ protected $fields = array(); public final function __set($name, $value) { $this->fields[$name] = $value; } public final function __get($name) { return $this->fields[$name]; } }
Передавая внутренний массив библиотеке ADODB мы можем автоматически генерировать SQL запросы для обновления записи в БД данным объектом, При этом, не нужны громоздкие конструкции маппинга полей таблиц БД на поля объекта сущности на основе XML и тому подобного. Нужно только чтобы имя поля совпадало со свойством объекта. Поскольку то, как именуются поля в БД и поля объекта, для компьютера значения не имеет, то нет никаких причин чтобы они не совпадали.
Покажем, как это работает в конечном варианте.
Код законченного класса расположен на Gist . Это абстрактный класс, содержащий минимум необходимого для работы с БД. Отмечу, что данный класс - упрощенная версия решения, отработанного на нескольких десятках проектов.
Представим, что у нас такая табличка:
CREATE TABLE `users` (`username` varchar(255) ,
`created` date ,
`user_id` int(11) NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`user_id`))
Тип БД не имеет значения - ADODB обеспечивает переносимость для всех распространенных серверов БД.
Создадим класс сущности Пользователь, на основе класса Entity
/** * @table=users * @keyfield=user_id */ class User extends Entity{ }
Собственно и все.
Используется просто:
$user = new User(); $user->username="Вася Пупкин"; $user->created=time(); $user->save(); //сохраняем в хранилище // загрузим опять $thesameuser = User::load($user->user_id); echo $thesameuser ->username;
Таблицу и ключевое поле указываем в псевдоаннотациях.
Также можем указать представление (к примеру, view =usersview) если, как это часто бывает, сущность выбирается на основе своей таблицы с приджойнеными или вычисляемыми полями. В этом случае выбираться данные будут из представления а обновляться будет таблица. Кому не нравятся такие аннотации могут переопределить метод getMetatada() и указать параметры таблицы в возвращаемом массиве.
Что еще полезного представляет класс Entity в данной реализации?
Например, мы можем переопределить метод init(), который вызывается после создания экземпляра Entity, чтобы инициализировать дату создания по умолчанию.
Или перегрузить метод afterLoad(), который автоматически вызывается после загрузки сущности из БД, чтобы преобразовать дату в timestamp для дальнейшего более удобного использования.
В результате получим не намного более сложную конструкцию.
/** * @table=users * @view=usersview * @keyfield=user_id */ class User extends Entity{ protected function init() { $this->created = time(); } protected function afterLoad() { $this->created = strtotime($this->created); } }
Также можно перегрузить методы beforeSave и beforeDelete и другие события жизненного цикла где можно, например, выполнить валидацию перед сохранением или какие нибудь другие действия - например, убрать за собой картинки из аплоада при удалении пользователя.
Загружаем список сущностей по критерию (по сути условия для WHERE).
$users = User::load("username like "Пупкин" ");
Также класс Entity позволяет выполнить произвольный, «нативный» так сказать SQL запрос. Например, мы хотим вернуть список пользователей с какими нибудь группировками по статистике. Какие конкретно поля вернутся, не имеет значения (главное чтобы там было user_id, если есть необходимость дальнейшей манипуляции сущностью), нужно только знать их наименования чтобы обратится к выбранным полям. При сохранении сущности, как очевидно из вышеприведенного, тоже не надо заполнять все поля, какие будут присутствовать в объекте сущности, те и пойдут в БД. То есть нам не нужно создавать дополнительные классы для произвольных выборок. Примерно как анонимные структуры при выборке в EF только здесь это тот же класс сущности со всеми методами бизнес-логики.
Строго говоря, вышеприведенные методы получения списков несколько выходят за пределы паттерна AR. По сути - это фабричные методы. Но как завещал старик Оккама, не будем плодить сущности сверх необходимого и городить отдельный Entity Manager или типа того.
Заметим что вышеприведенное - просто классы PHP и их можно как угодно расширять и модифицировать, дописывать в сущности (или базовый класс Entity) свойства и методы бизнес-логики. То есть мы получаем не просто копию строки таблицы БД, а именно бизнес-сущность как часть объектной архитектуры приложения.
Кому это может быть полезно? Разумеется, не прокачанным разрабам, которые считают что использование чего то проще доктрины - не солидно, и не перфекционистам, уверенным, что если решение не вытягивает миллиард обращений к Бд в секунду то это не решение. Судя по форумам, перед многими обычными разработчиками, работающими над обычными (коих 99.9%) проектами рано или поздно возникает проблема найти простой и удобный объектный способ для доступа к БД. Но сталкиваются с тем, что большинство решений либо неоправданно наворочены, либо являются частью какого-либо фреймворка.
P.S. Вынес решение из фреймворка отдельным проектом