Непонятные символы вместо текста в браузере. Что делать, если вместо текста иероглифы (в Word, браузере или текстовом документе) Почему в браузере буквы непонятные
Китайская письменность – иероглифическая. Встречаются иероглифы и в других языках, испытавших влияние Китая – японском и, в меньшей степени, корейском. Во вьетнамском языке иероглифическая письменность использовалась до XX века. Перед изучающими эти языки особенно остро стоит вопрос, сколько нужно знать иероглифов, как их запомнить и, главное, не забыть.
Иероглиф в классическом письменном языке вэньянь 文言 означал, как правило, целое слово. В современном китайском языке слова большей частью состоят из одного-двух, реже трех и более иероглифов. Поэтому иероглифов существует очень много.
В 1994 году был издан словарь «Море китайских иероглифов» Чжунхуа цзыхай 中華字海, в котором насчитывается 85568 иероглифов! Правда, подавляющую их часть можно встретить лишь несколько раз в классических литературных произведениях. Обычные двуязычные словари насчитывают около 6-8 тысяч иероглифов, среди которых также попадается немало редких. Более полные толковые словари насчитывают около 10-20 тысячи знаков.
Считается, что для понимания 80% современного обычного китайского текста достаточно знать 500 наиболее частотных иероглифов, знание 1000 иероглифов дает понимание примерно 91% текста, а 2500 иероглифов – 99% текста. Для того, чтобы сдать экзамен для иностранцев на знание китайского языка высшего уровня HSK 6, нужно знать чуть меньше 3000 иероглифов. Для чтения специальной научной или классической литературы нужно понимать большее количество иероглифов.
Однако надо иметь ввиду, что даже если все иероглифы в тексте вам знакомы, вы далеко не всегда абсолютно точно поймете смысл написанного. Нужно знать еще и слова — различные словосочетания иероглифов. В китайском языке используется довольно много сокращений, когда устойчивые словосочетания из нескольких иероглифов сокращаются до более коротких.
Так, например, словосочетание «Пекинский университет» 北京大学 Běijīng dàxué сокращается до 北大 Běidà , что буквально означает «северный большой». Другая сложность китайского языка — это использование чэнъюй 成语 — идиом, состоящих, как правило, из четырех иероглифов. При буквальном переводе каждого из знаков смысл сказанного может оказаться непонятым. Существуют специальные словари чэнюев, а также сборники рассказов, где поясняется смысл наиболее известных идиом. Переводы чэнъюй можно найти и в словарях.
В японском языке существует обязательный список иероглифов Дзёё кандзи 常用漢字, принятый Министерством образования Японии в качестве достаточного в повседневном употреблении. Он состоит из 2136 кандзи (иероглифов) и включает 1006 кёику кандзи , которые изучают школьники в 6-летней начальной школе и 1130 кандзи , которые учат в средней школе.
Структура иероглифа
На первый взгляд, иероглиф кажется хаотичным набором различных черт и точек. Однако это не так. Существует несколько базовых элементов, из которых состоит иероглиф. Прежде всего, это черты, из которых состоят графемы. Графемы, в свою очередь, формируют более сложный знак.
Черты
Любой иероглиф состоит из определенного набора черт. Сами по себе черты не имеют лексического значения и чтения. Всего существует четыре типа черт и более двух десятков их разновидностей:
- Простые (основные) черты: горизонтальная, вертикальная, наклонные влево и вправо, откидные влево и вправо, специальные точки.
- Черты с крюком: горизонтальная, вертикальная (могут быть с крюком влево или крюком вправо), откидная вправо.
- Ломанные черты: линия изменяет направление один и более раза, имеет сложную конфигурацию.
- Ломанные черты с крюком.
Встречаются и немного другие классификации черт, однако общей сути это не меняет. Черты в иероглифы пишутся в строго определенной последовательности: «сначала горизонтальная, потом вертикальная, сначала откидная влево, потом откидная вправо, сначала верхняя, затем нижняя, сначала слева, затем справа, сначала в середине, потом с двух сторон от неё, сначала входим внутрь, затем затворяем дверь» .

В прошлом иероглифы состояли из большого числа черт, запомнить их было непросто. Поэтому одной из целей реформы письменности, осуществленной китайским правительством в 60-х годах XX века, было упрощение иероглифов путем уменьшения количества черт.
Аналогичное упрощение иероглифов было осуществлено и в Японии. Однако упрощенные японские иероглифы не всегда соответствуют китайским, хотя зная полные и упрощенные варианты китайских иероглифов, обычно легко понять и японские упрощенные. Например, слово «библиотека», записанное китайским упрощенным письмом: 图书馆, китайским полным письмом: 圖書館 и на японском языке: 図書館. На китайском языке оно читается túshūguǎn , на японском — toshokan .
На Тайване, в Сингапуре и некоторых других местах по-прежнему пользуется полный вариант написания иероглифов. Да и в материковом Китае можно встретить тексты, записанные полными иероглифами. Кроме того, до сегодняшнего дня сохранились иероглифы, насчитывающие несколько десятков черт. Как правило, они редко употребляются и потому не были упрощены.
Наиболее сложным для написания считается иероглиф biáng (бян ), который состоит из более чем 60 черт. Он означает вид лапши, популярный в провинции Шэньси. За пределами региона этот иероглиф практически не используется, и потому он отсутствует в словарях и в компьютерных шрифтах.

Иероглиф «бян» считается самым сложным для написания. Рассказывают, что студенты одного из институтов в Чэнду систематически опаздывали на занятия. И профессор, разозлившись на них, велел каждому написать иероглиф «бян» тысячу раз. Сделать это смогли не все. И все слезно просили прощения, обещая впредь не опаздывать на занятия.
Графемы и ключи
Из черт формируются графемы – простые иероглифические знаки, обладающие устойчивыми лексическими значениями. Это базовые знаки китайской иероглифической письменности, из которых состоят китайские иероглифы. Они являются наиболее древними и выражают основные элементы окружающего мира и человека.
Примеры графем: человек 人 rén , женщина 女 nǚ , ребенок 子 zǐ , солнце 日 rì , небо 天 tiān , земля (почва) 土 tǔ и т.д.
Всего насчитывается около 300 графем, относительно их точного числа ученые-лингвисты расходятся в оценках. Большинство графем используются в современной китайской письменности в качестве наиболее употребительных знаков. Графемы составляют около 10% от числа наиболее употребительных иероглифов.
Помимо графем существуют ключи . Ключи – это основные классификационные знаки. Стандартный список ключей насчитывает 214 знаков. В него входят многие графемы и некоторые черты, не имеющие фиксированного значения. Таким образом, не все графемы являются ключами и не все ключи являются графемами.
Долгое время список из 214 ключей составлял так называемый иероглифический индекс, в соответствии с которым были упорядочены иероглифы в китайских словарях. Однако после того, как в КНР была введена упрощенная иероглифическая письменность, некоторые знаки подверглись либо частичному упрощению, либо структурным изменениям.
Для изучающих языки с иероглифической письменностью знание таблицы ключей является обязательным.
Сложные знаки
Большинство иероглифов состоят из двух или более графем. Традиционно их делят на две большие группы: идеографические знаки и фоноидеографические знаки.
Идеографические знаки
Идеографические знаки (идеограммы) состоят из двух и более графем. В них значение иероглифа является производным от семантики входящих в него графем, но чтение иероглифа никак не связано с ними. В современном китайском языке доля идеографических знаков составляет около 10%.
Примеры идеограмм:
- 好 hǎo (хорошо): 女 nǚ (женщина) и 子 zǐ (ребенок)
- 明 míng (понимание, просветление): 日 rì (солнце) и 月 yuè (луна)
- 休 xiū (отдых): 人 rén (человек) и 木 mù (дерево)
- 众 zhòng (толпа): три человека 人 rén
- 森 sēn (лес, чаща, густой): три дерева 木 mù
Фоноидеографические знаки
Около 80% иероглифов составляют так называемые фоноидеографические знаки, или фоноидеограммы. Иероглифы такого типа обычно состоят из двух частей. Одна часть называется семантическим множителем , или иероглифическим ключом . Она указывает на принадлежность иероглифа к определенной группе семантически родственных знаков и тем самым подсказывает приблизительное значение.
Другая часть иероглифа называется фонетиком и подсказывает приблизительное чтение. После реформы китайской письменности значительно возросло число фоноидеограмм, состоящих из двух графем, что значительно облегчило запоминание иероглифов.
Примеры фоноидеограмм:
- 妈 mā (мама): 女 nǚ (женщина — ключ ) и 马 mǎ (лошадь — фонетик )
- 性 xìng (природа, характер, род): 心 xīn (сердце, сознание — ключ ) и 生 shēng (рождение — фонетик )
- 河 hé (река): 水 shuǐ (вода, в иероглифе «река» элемент «вода» в позиции слева меняется на откидную черту с двумя точками — ключ ) и 可 kě (модальный глагол возможности или долженствования — фонетик )
Однако в процессе развития чтение многих иероглифов изменилось и в настоящее время далеко не всегда можно догадаться даже о приблизительном чтении иероглифа. Тем более, если речь идет о .
Легкие способы запомнить написание иероглифов
Думаю, вы убедились, что иероглиф имеет четкую структуру, в нем не может быть случайных элементов. Это помогает довольно легко запомнить написание и значение иероглифов.
Графемы восходят к пиктограммам, представляя собой видоизмененные, предельно упрощенные и абстрактные рисунки. В интернете можно найти немало картинок, показывающих, как постепенно изображение становилось все более отвлеченным и абстрактным. Это помогает быстрому запоминанию.

Наиболее древние иероглифы, от которых произошли современные, датируются серединой II тыс. до н.э. Это иньские гадательные надписи на костях животных и панцирях черепах. Постепенно изображения становились все более абстрактными, пока не приобрели современное написание
- 人 rén человек: две ножки и тело
- 大 dà большой: человек раскинул руки
- 天 tiān небо: что-то большое над большим человеком (вариант: Единое над большим человеком)
- 山 shān гора: три пика
- 口 kǒu рот: держи рот шире
- 曰 yuē говорить: язык во рту
- 竹 zhú бамбук: напоминает два бамбука
Когда я только начинала изучение китайского языка в университете, мы сперва изучили список из 214 ключей. Их я прописывала помногу раз, стараясь писать красиво, запомнить правильный порядок черт, который строго фиксирован. На это не стоит жалеть времени.
Изучив ключи, нетрудно запомнить сложные знаки – идеограммы и фоноидеограммы. Можно придумать историю, которая позволит навсегда запомнить полные иероглифы с большим количеством черт.
Примеры запоминания:
- 妈 mā мама — женщина 女 nǚ , которая работает как лошадь 马 mǎ
- 好 hǎo хорошо — когда женщина 女 nǚ рожает ребенка 子 zǐ
- 江 jiāng река — вода 水 shuǐ , которая делает работу 工 gōng (иероглиф «река» — пример фоноидеограммы, где чтение фонетика «работа» со временем изменилось)
- 仙 xiān святой, бессмертный — человек 人 rén , который живет в горах 山 shān
- 怕 pà бояться – сердце 心 xīn побелело 白 bái от страха
- 休 xiū отдых — человек 人 rén прилег отдохнуть под деревом 木 mù
- 难 nán трудный – трудно правой рукой (снова) 又 yòu поймать короткохвостую птицу 隹 zhuī
- 国 guó государство – правитель с копьем 玉 yù (нефрит, символ императорской власти) за оградой 囗 (без чтения).
Главное, дать волю фантазии. Со временем это войдет в привычку и для запоминания иероглифа достаточно будет просто запомнить названия графем, входящих в его состав.
А вот пример запоминания полного написания иероглифа «любовь» 愛 ài . Если разбить его на составные элементы, добавить немного шутки, то получится такая фраза: «когти в сердце вонзились, ножки подкосились, тут и крышка настала».
Или вот как можно запомнить иероглиф 腻 nì . Его словарные значения – «сало, грязь, лоснящийся, глянцевый, гладкий». Он состоит из графем «луна» (очень похожая на неё – «мясо»), «раковина», «стрелять из лука» и «два». Можно придумать историю: человек подстрелил из лука дичь (лоснящееся мясо, жирное, блестящее, с большим количеством сала), и продал её за две раковины (в древности – деньги) японцу. Как раз по-японски «два» читается как ни .
Чем более смешная, нелепая получится история, тем легче вы запомните иероглифы.
Кроме того, очень часто подобный разбор иероглифов помогает глубже прояснить смысл сложнейших и многозначных категорий китайской философии и культуры. На своих лекциях по китайской философии я часто прибегаю к такому способу объяснения.
- путь, дорога, тракт; путевой, дорожный; по дороге, на пути
- путь, маршрут; тракт; астр. путь небесного тела, орбита; анат., мед. тракт
- пути, направление деятельности; путь, способ, метод; подход; средство; правило, обычай
- техника, искусство; уловка, хитрость; трюк
- идея, мысль; учение; доктрина; догмат
- резон, основание; правота; правда, истина
- филос . Дао, истинный путь, высший принцип, совершенство
- даосизм, учение даосов; даосский монах, даос
- буддийское учение.
И это далеко не все значения! Однако если разбить иероглиф на входящие в него графемы, то все значения станут интуитивно понятны. Первая графема – 首 shǒu , «голова, макушка, начало, главное, основное, суть». Вторая – «продвигаться вперед». То есть Дао – нечто основное, что продвигается вперед, находится в движении.
Или, другой пример, важнейшая 仁 rén — человеколюбие, гуманность . Иероглиф состоит из двух графем: человек 人 rén и два 二 èr . И читается так же как «человек». То есть человеколюбие – это отношения между людьми, которые строятся на основе справедливости. Как говорил , «Только обладающий человеколюбием может любить людей и ненавидеть людей» («Лунь юй», IV, 3).

Одно из любимых занятий китайцев — писать иероглифы кистью, смоченной водой. Причем здесь иероглифы вдобавок написаны в зеркальном отображении!
Как запомнить чтение иероглифов
Хотя в китайском языке большинство иероглифов относится к категории фоноидеограмм, тем не менее, иероглиф не содержит прямого указания на чтение, как фонетические языки. Еще одна трудность китайского языка заключается в широком распространении явления омофонии: из-за ограниченного количества слогов (немногим более 400), разные иероглифы могут читаться одинаково, что создает определенные трудности в понимании устной речи. Тем не менее, очень удобно запоминать целый ряд иероглифов, имеющих одинаковое чтение.
На первых порах своего изучения китайского языка тон я обычно запоминала по какой-нибудь черте: горизонтальная черта в верхней части иероглифа означала первый тон, наклонная влево — второй тон, горизонтальная внизу — третий тон, наклонная или откидная вправо — четвертый тон. Хотя встречались иероглифы, где нужной черты не находилось.
Совершенно иная ситуация складывается в японском языке, где существует два вида чтения иероглифов: онное , пришедшее из китайского языка, и кунное , традиционное японское. Таким образом, один иероглиф может иметь до 5 и более различных чтений! В разных словосочетаниях иероглифы могут читаться по-разному.
Например, в японском языке слова «вчера» 昨日 и «завтра» 明日, имеющие в своем составе одинаковый знак 日 (день, солнце), читаются абсолютно по-разному: kino: и ashita соответственно. В словосочетании «каждый день», «ежедневно» 毎日 будет читаться mainichi , «третье число», «три дня» 三日- mikka . Хотя, по идее, все четыре слова должны были бы оканчиваться одинаково.
Именно поэтому единственный действенный способ и в китайском, и в японском языке запомнить чтение иероглифов — это зубрежка : многократно проговаривать их про себя и вслух, пытаться запомнить мелодику. В китайском языке это сделать, на мой взгляд, проще в силу наличия фоноидеограмм и общей повторяемости слогов, в японском — чуть сложнее.
Легко ли учить японские иероглифы после китайских?
Для тех, кто владеет китайским языком, японский язык со стороны кажется проще, по крайней мере, в части иероглифики. Действительно, значительная часть иероглифов в японском языке пишется одинаково с китайскими или очень похоже. Особенно, если знаешь полный вариант написания китайских иероглифов. Однако, как всегда, дьявол кроется в деталях. Расскажу о том, что я обнаружила уже на первых порах своего изучения японского языка.
В этой статье рассмотрено, почему вместо русских букв, возникают квадратики, непонятные символы, кракозябры, вопросительные знаки, точки, каракули или кубики в windows 7, vista, XP?
Что делать, чтобы избавиться от этих явлений? Универсального рецепта — нет. Много зависит от версии виндовс, да и самой сборки.
Первая причина, почему такое происходит – сбой кодировок. Нарушается целостность реестра, и происходят сбои. Только не всегда это основной источник.
Часто бывает, что даже на ново установленной операционной системе, после запуска некоторых программ вместо русских букв возникают квадратики, непонятные символы, крякозябры, вопросительные знаки, точки, каракули или кубики.
Если же проблема с цифрами, тогда она быстро , а избавиться от знаков вопросов вместо нормальных букв поможет эта .
Особенно часто такое случается после установки русификаторов. Народные «умельцы», не учитывают все, а возможно и переводы делают только под одну операциоку.
Возможно и не это главное, если учесть, что все заключаться в кодировке. Может программа, просто не поддерживает определенные буквы.
Хотя это и удивительно, но по умолчанию операционная система windows 7 вместо русских букв в некоторых программа отображает квадратики, непонятные символы, кракозябры, вопросительные знаки, точки, каракули или кубики.
Я всегда после переустановки вношу изменения в реестр, даже если все работает нормально. В будущем проблем с непонятными символами не возникает.
Устранение проблемы через реестр
Сделать такую манипуляцию очень легко. Для этого скачиваем и запускаем первый файл.
Подчеркиваю, только первый, второй — если после первого непонятные символы, иероглифы или кракозябры не пропадут и не появляться нормальные русские буквы.

Только не забудьте после внесения изменений в реестр системы компьютер перезагрузить, иначе изменений не ждите.
Есть еще несколько способов изменить кодировку, но лучше их не делать, поскольку это будет перекладывание ноши (груза) с больного места на нездоровое.
Программа что в данный момент отображает кракозябры, иероглифы и вообще непонятно что, может начать работать, а вот русские буквы в других нарушаться.
На всякий случай можете попробовать переименовать файлы «c_1252.nls….. c_1255.nls ». добавьте к ним в самый конец «bak» Должно выглядеть так c_1252.nls.bak». Сделайте так с всеми четырьмя. Они находятся по такому пути: C:\Windows\System32.
Хочется сказать, что я переустановил не менее 100 виндовс 7. Правда, почти все были 32 (86) максимум. Были проблемы с отображением русских букв.
Особенно это касалось программ. В некоторых появлялись, возникают вопросы, квадратики, непонятные символы, кракозябры, вопросительные знаки, точки, каракули или кубики, но описанный самый первый способ помогал всегда.
Также квадратики, непонятные символы, кракозябры, вопросительные знаки, точки, каракули или кубики могут появиться в или skyrim.
Такое получается, из-за несовпадения форматов (кодировок). Их можно устанавливать самостоятельно для каждого случая отдельно (в ручном режиме) Смотрите на рис:

В самом верху нажмите «файл», после чего подведите курсор к месту «кодировка» и нажав измените. Успехов.
Задаём набор символов
Мета-тег
Нужно добавить на каждую страницу (или в шаблон шапки) специальный мета-тег, сообщающий браузеру о том, какой набор символов ему использовать для отображения текстов. Тег этот стандартный и выглядит обычно так:
charset=UTF-8 » />
charset=»utf-8″ /> (вариант для HTML 5)
Надо вставить его в раздел
— лучше в самое начало, сразу после открывающего :
Мета-тег кодировки
Через.htaccess (если ничего не помогает)
Обычно первых двух вариантов достаточно и браузеры отображают текст как надо . Но с некоторыми из них могут быть проблемы и поэтому можно прибегнуть к помощи файла.htaccess .
Для этого в нём нужно прописать такую строчку:
AddDefaultCharset utf-8
Вот и всё. Если вы примените последовательно 3 этих способа задания кодировки на своём проекте, то вероятность того, что всё будет отображено как надо , близка к 100 %.
Как «увидеть», что скрывается за непонятными символами на сайте?
Если вы зашли на веб-страницу, видите «кракозябры» и хотите увидеть нормальный текст, то тут только два пути:
- сообщить сайтовладельцу, чтобы всё настроил как следует
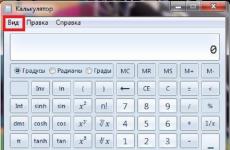
- попытаться угадать кодировку самостоятельно. Делается это стандартными средствами браузеров. В Chrome, например, нужно в меню щёлкнуть «Инструменты => Кодировка» и из огромного списка выбрать подходящий набор символов (т.е. угадать).
К счастью, практически все современные веб-проекты делаются в кодировке UTF-8, которая является «универсальной» для разных алфавитов и поэтому всё менее и менее вероятно увидеть эти непонятные символы в Интернет.
Здравствуйте, уважаемые читатели, почитатели и прочие хорошие люди!
Случалось ли Вам получать и читать письма на “фиг каком пойми языке” или заходить на какой-нибудь интернет-ресурс и вместо привычных букв видеть сплошные кракозябры? Если да, тогда эта заметка для Вас, ибо в ней мы поговорим о кодировке страниц, её форматах, почему оная возникает и как впредь избежать непонятных иероглифов.
Итак, сегодня нас ждет не легкая софтовая статья, а суровая техническая, так что приготовьтесь: будем немного ударяться в суровые реалии.
Поехали.
Что такое кодировка текста и с чем ее едят?
Начать хотелось бы с того, что этой статьи могло бы и не быть, т.к. компьютерно-юзательная жизнь автора этих строк протекала вполне себе спокойно и достойно. Но вот в один прекрасный день, шляясь по просторам сети Интернет не со своего ПК, я столкнулся с непонятными явлениями на некоторых сайтах. Заходя на интернет-ресурсы, я видел не привычный нам русский алфавит и красивый понятный текст, а какую-то ересь в виде непонятной последовательности символов. Выглядела она примерно вот так (см. изображение).

Сначала я подумал, что моя любимая Мозилка (браузер Firefox) перегрелась и ей пора вызывать неотложку, но потом начал понимать, что проблема, скорее всего, на стороне ресурса сети и кроется она в неправильно настроенной кодировке. Это действительно оказалось так, и пошаманив немного с бубном, проблемка была оперативно решена. Результатом же всех моих любовных похождений и стал сегодняшний материал. Собственно, поехали разбираться в деталях.
Всю информацию, представленную в цифровом виде и находящуюся в глобальной паутине, нужно рассматривать с двух сторон: первая - со стороны пользователя (красивый и ухоженный текст на экране монитора) и вторая – со стороны поисковой машины (некий программный код, состоящий из различных тегов/метатегов, таблицы символов и прочее).
Если Вы хоть немного знакомы с языком разметки гипертекста (HTML ), то должны быть в курсе, что сайт глазами поисковых машин (Google, Яндекс ) видится не как обычный текст, а как структурированный документ, состоящий из последовательностей различного рода тегов. Чтобы было понятней, о чем я говорю, давайте взглянем на всеми нами любимый сайт Заметки Сис.Админа ” проекта , но не глазами обычного пользователя, а "глазами" поисковика. Для этого нажимаем сочетание клавиш Сtrl+U (для браузеров Firefox и Chrome ) и видим следующую картину (см. изображение):

Перед нами машинный вариант сайт , вот в таком вот непрезентабельном виде он подается поисковым системам и именно в таком виде они его и кушают. Если бы мы просто взяли и “засандалили” варианты статей из блокнота или Word обычным текстом, машины бы им не то что подавились, они бы даже и есть его не стали. Итак, перед нами главная страница проекта в HTML -виде. Обратите внимание на строку с надписью UTF-8 , это не что иное, как пресловутая кодировка текста страницы, именно она и отвечает за формат вывода информации в презентабельном виде, в результате чего через браузер мы видим нормальный текст.
Теперь давайте разберемся, почему же происходит так, что порой на экране монитора мы видим кракозябры. Все очень просто, проблема кроется в открытии файла в неверной кодировке. Если перевести на бытовой язык, то допустим Вас послали в магазин за молоком, а Вы притарабанили хлеб, вроде бы тоже съестное, но совсем другой формат продукта.
Итак, теперь давайте разбираться с теорией и для этого введем некоторые определения.
- Кодировка (или “Charset ”) – соответствие набора символов набору числовых значений. Нужна для “сливания” информации в интернет, т.е. текстовая информация преобразуется в биты данных;
- Кодовая страница (“Codepage ”) – 1 байтовая (8 бит) кодировка;
- Количество значений, принимаемое 1 байтом – 256 (два в восьмой).
Соответствие “символ-изображение” задается с помощью специальных кодовых таблиц, где каждому символу уже присвоен свой конкретный числовой код. Таких таблиц существует достаточно много, и в разных таблицах один и тот же символ может идентифицироваться по-разному (ему могут соответствовать разные числовые коды).
Все кодировки различаются количеством байт и набором специальных знаков, в которые преобразуется каждый символ исходного текста.
Примечание:
Декодирование – операция, в результате которой происходит преобразование кода символа в изображение. В результате этой операции информация выводится на экран монитора пользователя.
В общем.. С определениями разобрались, а теперь давайте узнаем, какие же (кодировки) бывают.
Виды кодировок текста
А их, в общем-то, хватает.
- ASCII
Одной из самых “древних” считается американская кодировочная таблица (ASCII , читается как “аски”), принятая национальным институтом стандартов. Для кодировки она использовала 7 битов, в первых 128 значениях размещался английский алфавит (в нижнем и верхнем регистрах), а также знаки, цифры и символы. Она больше подходила для англоязычных пользователей и не была универсальной.
- Кириллица
Отечественный вариант кодировки, для которого стали использовать вторую часть кодовой таблицы – символы с 129 по 256 . Заточена под русскоязычную аудиторию.
- Кодировки семейства MS Windows : Windows 1250-1258 .
8-битные кодировки, появились как следствие разработки самой популярной операционной системы, Windows . Номера с 1250 по 1258 указывают на язык, под который они заточены, например, 1250 – для языков центральной Европы; 1251 – кириллический алфавит.
- Код обмена информацией 8 бит – КОИ8
KOI8-R, KOI8-U, KOI-7 – стандарт для русской кириллицы в юникс-подобных операционных системах.
- Юникод (Unicode )
Универсальный стандарт кодирования символов, позволяющий описать знаки практически всех письменных языков. Обозначение “U+xxxx ” (хххх – 16-ричные цифры). Самые распространенные семейства кодировок UTF (Unicode Transformation Format) : UTF-8, 16, 32 .
В настоящее время, как говорится, “рулит” UTF-8 – именно она обеспечивают наилучшую совместимость со старыми ОС , которые использовали 8 -битные символы. В UTF-8 кодировке находятся большинство сайтов в сети Интернет и именно этот стандарт является универсальным (поддержка кириллицы и латиницы).
Разумеется, я привел не все виды кодировок, а только наиболее ходовые. Если же Вы хотите для общего развития знать их все, то полный список можно отыскать в самом браузере. Для этого достаточно пройти в нем на вкладку “Вид-Кодировка-Выбрать список ” и ознакомиться со всевозможными их вариантами (см. изображение).

Думаю возник резонный вопрос: “Какого лешего столько кодировок? ”. Их изобилие и причины возникновения можно сравнить с таким явлением, как кроссбраузерность/кроссплатформенность. Это когда один и тот же сайт сайт отображается по-разному в различных интернет-обозревателях и на различных гаджет-устройствах. Кстати у сайта "Заметки Сис.Админа " с этим, как Вы заметили всё в порядке:).
Все эти кодировки – рабочие варианты, созданные разработчиками “под себя” и решение своих задач. Когда же их количество перевалило за все разумные пределы, а в поисковиках стали плодиться запросы типа: “Как убрать кракозябры в браузере? ” - разработчики стали ломать голову над приведением всей этой каши к единому стандарту, чтобы, так сказать, всем было хорошо. И кодировка Unicode , в общем-то, это “хорошо” и сделала. Теперь если такие проблемы и возникают, то они носят локальный характер, и не знают как их исправить только совсем непросвещенные пользователи (впрочем, часто беда с кодировкой и отображением сайтов появляется из-за того, что веб-мастер указал на стороне сервера некорректный формат, и приходится переключать кодировку в браузере).
Ну вот, собственно, пока вся "базово необходимая" теория, которая позволит Вам “не плавать” в кодировочных вопросах, теперь переходим к практической части статьи.
Решаем проблемы с кодировкой или как убрать кракозябры?
Итак, наша статья была бы неполной, если бы мы не затронули пользовательско-бытовые вопросы. Давайте их и рассмотрим и начнем с того, как (с помощью чего) можно посмотреть кодировку?
В любой операционной системе имеется таблица символов, ее не нужно докачивать, устанавливать – это данность свыше, которая располагается по адресу: “Пуск-программы-стандартные-служебные-таблица символов”. Это таблица векторных форм всех установленных в Вашей операционной системе шрифтов.

Выбрав “дополнительные параметры” (набор Unicode ) и соответствующий тип начертания шрифта, Вы увидите полный набор символов, в него входящих. Кликнув по любому символу, Вы увидите его код в формате UTF-16 , состоящий из 4 -х шестнадцатеричных цифр (см. изображение).

Теперь пара слов о том, как убрать кракозябры. Они могут возникать в двух случаях:
- Со стороны пользователя - при чтении информации в интернет (например, при заходе на сайт);
- Или, как говорилось чуть выше, со стороны веб-мастера (например, при создании/редактировании текстовых файлов с поддержкой синтаксиса языков программирования в программе ++ или из-за указания неправильной кодировки в коде сайта).
Рассмотрим оба варианта.
№1. Иероглифы со стороны пользователя.
Допустим, Вы запустили ОС и в каком-то из приложений у Вас отображаются пресловутые каракули. Чтобы это исправить, идем по адресу: “Пуск - Панель управления - Язык и региональные стандарты - Изменение языка
” и выбираем из списка, "Россия
".

Также проверьте во всех вкладках, чтобы локализация была “Россия/русский ” – это так называемая системная локаль.
Если Вы открыли сайт и вдруг поняли, что почитать информацию Вам не дают иероглифы, тогда стоит поменять кодировку средствами браузера (“Вид - Кодировка ”). На какую? Тут все зависит от вида этих кракозябр. Ориентируйтесь на следующую шпаргалку (см. изображение).

№2. Иероглифы со стороны веб-мастера.
Очень часто начинающие разработчики сайтов не придают большого значения кодировке создаваемого документа, в результате чего потом и сталкиваются с вышеозначенной проблемой. Вот несколько простых базовых советов для веб-мастеров, чтобы исправить беду.
Чтобы такого не происходило, заходим в редактор Notepad++ и выбираем в меню пункт “Кодировки ”. Именно он поможет преобразовать имеющийся документ. Спрашивается, какой? Чаще всего (если сайт на WordPress или Joomla ), то “Преобразовать в UTF-8 без BOM ” (см. изображение).

Сделав такое преобразование, Вы увидите изменения в строке статуса программы.
Также во избежание кракозябр необходимо принудительно прописать информацию о кодировке в шапке сайта. Тем самым Вы укажите браузеру на то, что сайт стоит считывать именно в прописанной кодировке. Начинающему веб-мастеру необходимо понимать, что чехарда с кодировкой чаще всего возникает из-за несоответствия настроек сервера настройкам сайта, т.е. на сервере в базе данных прописана одна кодировка, а сайт отдает страницы в браузер в совершенной другой.
Для этого необходимо прописать “внаглую” (в шапку сайта, т.е, как частенько, в файл header.php ) между тегами
следующую строчку:Прописав такую строчку, Вы заставите браузер правильно интерпретировать кодировку, и иероглифы пропадут.
Также может потребоваться корректировка вывода данных из БД (MySQL). Делается сие так:
mysql_query("SET NAMES utf8");
myqsl_query("SET CHARACTER SET utf8");
mysql_query("SET COLLATION_CONNECTION="utf8_general_ci"" ");
Как вариант, можно еще сделать ход конём и прописать в файл .htaccess такие вот строчки:
# BEGIN UTF8
AddDefaultCharset utf-8
AddCharset utf-8 *
CharsetSourceEnc utf-8
CharsetDefault utf-8
# END UTF8Все вышеприведенные методы (или некоторые из них), скорее всего, помогут Вам и Вашим будущим посетителям избавиться от ненавистных иероглифов и проблем с кодировкой. К сожалению, более подробно мы здесь инструкцию по веб-мастерским штукам рассматривать не будем, думаю, что они обязательно разберутся в подробностях при желании (как-никак у нас несколько другая тематика сайта).
Ну, вот и практическая часть статьи закончена, осталось подвести небольшие итоги.
Послесловие
Сегодня мы познакомились с таким понятием, как кодировка текста. Уверен, теперь при возникновении каракулей на мониторе компьютера Вы не спасуете, а вспомните все приведенные здесь методы и решите вопрос в свою пользу!
На сим все, спасибо за внимание и до новых встреч.
Когда я только начинал изучать тему разработки сайтов, кракозябры были одной из моих постоянных проблем. Создал HTML-страницу — в браузере кракозябры, установил денвер и попробовал создать сайт на PHP — снова вместо букв кракозябры. Скачал иностранную тему, подключился к базе данных — та же проблема.
На своих сайтах я обычно использую UTF-8 (это такая кодировка текста, она ещё называется юникод), соответственно она будет присутствовать во всех примерах в этой статье.
1. UTF-8 без BOM
Начнём с самой простой проблемы. Вы создали какой-то HTML-файл, открыли его в браузере и получили:
Кракозябры (проблема с кодировкой).
Проблема актуальна в основном для пользователей Windows, на маке я с таким ни разу не сталкивался.
Решение проблемы зависит в основном от того, каким редактором вы пользуетесь. Для пользователей Windows я рекомендую бесплатный офигительный Notepad++.
Значит, открываем файл в Notepad++ и переходим в Кодировки > Преобразовать в UTF-8 без BOM. Вопрос — почему без BOM? Потому что с BOM у вас будут постоянно вставляться пустые символы (на самом деле они не пустые, у них тоже есть своя функция, но нам она в данном случае не нужна) куда не надо, а для PHP это уже критично.
2. Мета тег charset
Если вы сделали то, что я описывал в предыдущем шаге и ваша проблема не разрешилась, тогда самое время испробовать второй метод устранения кракозябров.
Всё, что нам требуется, это вставить следующий код между тегами
сайта. Прежде всего проверьте, возможно этот метатег у вас уже присутствует. Если да, то посмотрите какое у него стоит значение параметра charset.3. .htaccess
Если русские буквы до сих пор отображаются кракозябрами, тогда открываем ваш.htaccess , который лежит в корне сайта и вставляем туда с новой строки это:
Важно! Этот код должен вставляться до того, как будет что-либо выведено на странице сайта, иначе — ошибка.
5. Проблемы с последним символом при обрезке строки
Как решить эту проблему?
Легко — всё что нам нужно, это найти функцию substr() в коде и поменять её на mb_substr() .
Если после этого у вас полезут ошибки на сайт, то скорее всего multibyte-функции не поддерживаются вашим хостингом, первое, что вам следует сделать, это написать в супорт и спросить, нельзя ли их подключить на ваш аккаунт. Если нет, меняем хостинг, например на тот, которым .
6. MySQL
У меня не раз бывало такое, что я подключался к MySQL, вытаскивал какие-нибудь данные, и при их выводе на сайте, текст отображался кракозябрами.